Trying to organize a large product backlog is a tough thing to do. As times goes by, and the product grows, what was once a simple list of prioritized items gets unwieldy.
Working from a huge list makes it very difficult to navigate and very easy to get “lost” in it. You lose track of what’s going on, what should come next and what’s really low priority. Duplication abounds. None of this is helped by the fact that the backlog keeps growing: as higher priority items get done, new work is added and older items accumulate further down.
A self-inflicted problem
We’re creating problems for ourselves through the amount of stuff we put in the backlog and by structuring it as a list — let’s go over each of these.
First, there’s our tendency to keep everything on the backlog. Every idea, request, bug, maintenance chore, user story, you name it — gets included. We say to ourselves that we can always groom it later on (but we don’t.) We’re also not helping when we use the backlog as the standard (non) answer to requests from stakeholders — “sure, I’ll put your <pet feature> on the backlog and consider it for <some future release>.”
Then, there’s the issue with how we structure it. We gravitate towards a list probably because of Agile methodologies, or maybe because that’s the natural way to think about work to be done. The thing is that although the team can work off a list on a given sprint or release cycle, it’s a terrible format to manage the multi-dimensional beast that is the backlog.
Proposing a Way Out
Having established the two main reasons that lead us to a chaotic backlog, it’s time to discuss how we can avoid these pitfalls.
Adding Dimensions for a Richer Structure and Navigation
The backlog is a prioritized store of work to be done on the product, but if we are to overcome its List form, then what shape should it take?
Story mapping is a great approach, but I think it works best for well defined projects that won’t be subject to much change in scope as you build them. When you’re working on a product with an ever-moving scope, going into such detail is probably wasteful. On the other hand, this sort of multi-dimensional thinking is definitely the right way to imagine a backlog.
We can start out by considering a large product backlog to be something that has both Length and Width:
- Length refers to the amount of things to do (and the classical list shape);
- Width refers to the different product areas, modules or initiatives it encompasses. It’s any way you can group a set of interrelated items.
These two dimensions are common to backlogs of any size. Even if you’re working on a smaller product that may not be Wide*, it can still be Long — the analogy still applies, it’s just a simplification.
Being a backlog, it’s important that each of these dimensions is prioritized: just as some items have higher priorities than others, the same can be said for some product areas and initiatives vs the others.
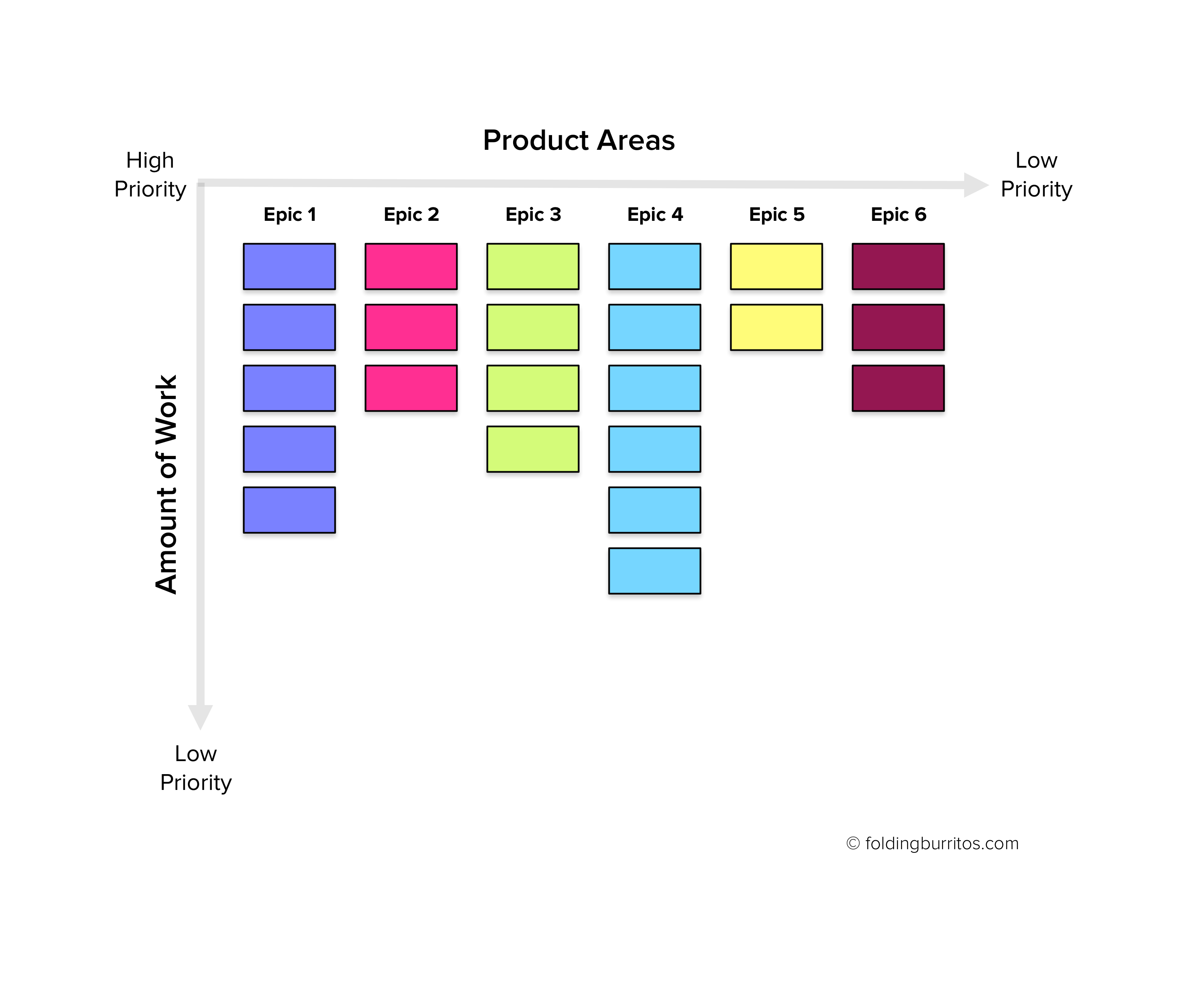
Combining these factors is a great step forward in creating something that is easier to navigate and understand, but it’s still not enough:
- It is too low level for us to create (and track) our roadmap, as we need to know which initiatives and features will be released over time;
- It is too high level to use as our actual development backlog, because at the end of the day we do need a single prioritized list for our team to develop.
To help with this, we need to add another dimension: Depth. It will represent different levels of granularity in how we look at our backlog:
- The high-level initiatives/themes/epics we’ll be working on “Now”, “Later” and “Next” [1];
- Breaking down each initiative/theme/epic into lower level items and user stories;
- Individual user stories and tasks that end up on our actual development backlog.
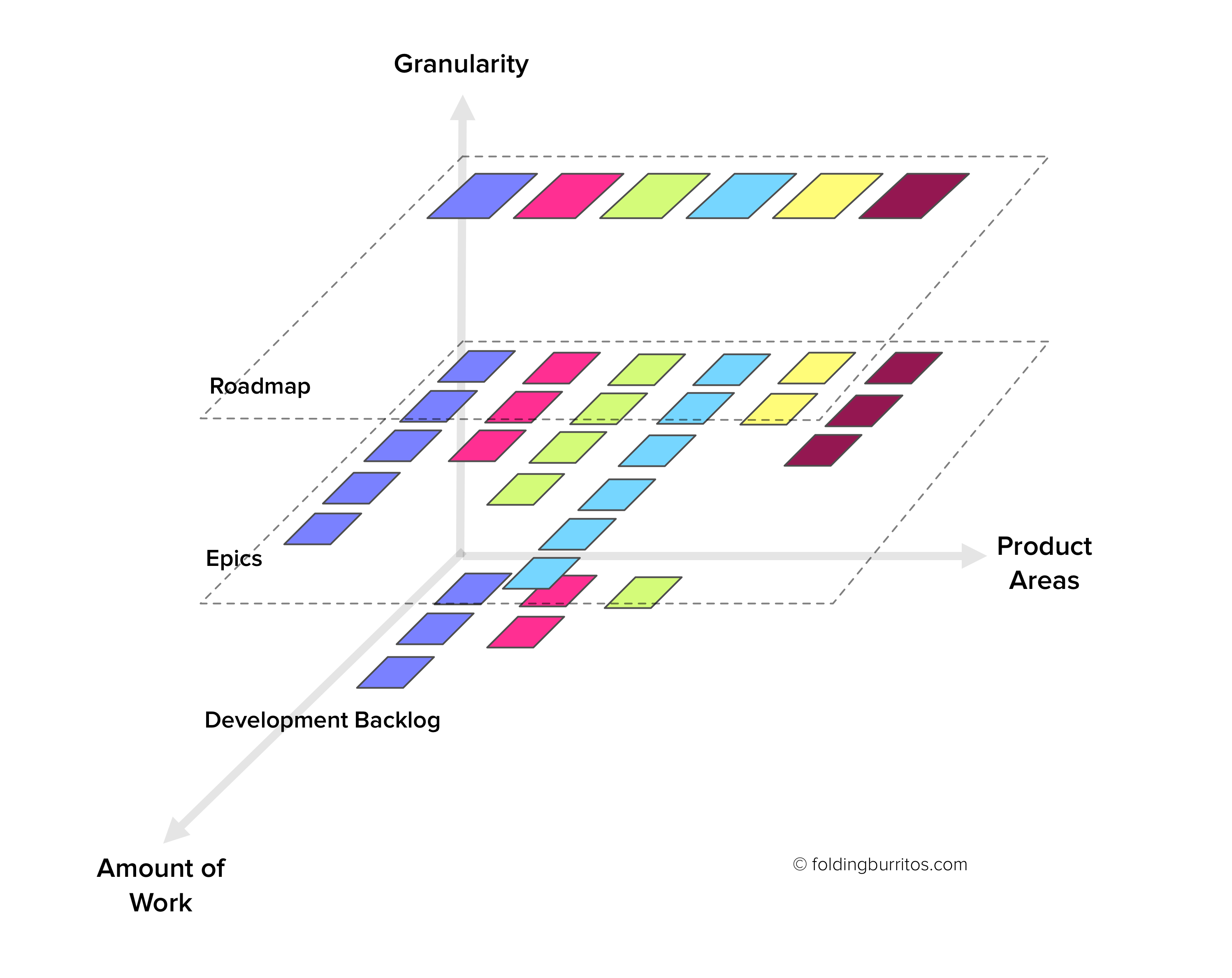
Having this rich structure for our backlog should enable us to slice and dice through it much more efficiently and effectively. (In case you’re wondering how this translates into practical terms, I’ll describe how you can set up this type of structure using Trello in just a little bit.)
Keeping it Lean
Having a fancy 3D view for our backlog is not enough. As we saw before, we also need to control what gets on the backlog and how long it stays there.
Think of the backlog as the set of things that you believe should end up on the product in the very near term. Anything else should stay out. Don’t be a backlog hoarder.
Every input, idea and feature request you get from the outside world (customers, executives, other teams, etc.) should end up in some sort of “waiting room” or DMZ. It should never go straight to the backlog. After you’ve validated that it’s actually useful and/or important, then go ahead and include it.
Also, any items that have been waiting to be done for more than 6 to 12 months, should be ruthlessly archived or sent back the waiting room. If they clearly aren’t important enough to be done, then they definitely don’t belong on the backlog.
A Real-World Workflow to Keep an Organized Backlog
What I’ve described so far doesn’t need to stay theoretical. You can setup this kind of workflow using Trello[2]. Here’s how we do it:
- Our team follows a workflow heavily inspired by the one used at UserVoice;
- We keep 4 main boards:
- Roadmap — it contains 2 or 3 lists, each representing the epics we’ll be working on over the next 2 to 3 quarters [3]. Each card on each list is an epic. Within the list corresponding to the current quarter, each card contains checklists with items pointing to cards in the following board (we don’t go into such detail for epics on future quarters);
- Epics — contains lists for each epic we’re working on in the current quarter. Each list contains the specific user stories and tasks that compose that epic;
- Engineering — this board is owned by the team and contains tech debt and other architectural issues the team identifies as they move forward;
- Kanban — contains our Kanban workflow, with lists representing each step in our process. There’s a single development backlog list, which is fed from the Epics and Engineering boards, after negotiation between the team and myself.
- We also keep a supporting board called Sandbox — it is where we keep every suggestion and feature request we get. It’s not considered to be part of the backlog;
- The final development backlog is usually kept short, with few items in it. The goal is to avoid having to send back items to the Epics or Engineering boards if priorities change. Ideally, only items we’re completely sure will get done end up there;
- I routinely groom the Roadmap and Epics boards, as priorities change;
- Every once in a while, I check the Sandbox for ideas to validate and possibly include on the Roadmap;
- Any card that stays on a board for more than 6 months or so, gets deleted or sent to the Sandbox.
This workflow isn’t perfect and we keep tweaking it over time. In spite of that, it has proven to be a strong solution to organize and navigate a very large backlog.
You should really check out this presentation on roadmapping by Janna Bastow (of Mind the Product and ProdPad fame) ↩︎
If you haven’t yet tried it or have been living underground, Trello is a very flexible tool that you can shape into a lot of different workflows. It’s also a particularly well made piece of software. ↩︎
Despite Janna Bastow’s very wise advice to avoid dates on roadmaps, our team can’t avoid them due to stakeholder pressure. To counterbalance this, we work in the broadest date terms we can: quarters. ↩︎